0x00 集合框架
集合框架是Java提供的一套用于存储和操作对象组的统一架构,它提供了各种数据结构和实现,例如列表,集合。
1. List集合
List有序集合,允许重复元素
创建方式:对象创建,new
主类
这种方式为最基础的创建方式,可以是任意类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
//List有序集合,允许重复元素
//创建方式对象创建,new
List list = new ArrayList();
list.add("苹果");
list.add("香蕉");
list.add(1);
System.out.println(list);
}
}
|
输出
设置自定义元素
<String>:泛型指定元素
可以看到,当我们指定了String类型之后,我们使用其他元素之后就会报错
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
//List有序集合,允许重复元素
//创建方式对象创建,new
List<String> list = new ArrayList();
list.add("苹果");
list.add("香蕉");
list.add(1);
System.out.println(list);
}
}
|

集合的第一个特性
这里我创建一个数组,看一下List和数组到底有什么区别
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
//List有序集合,允许重复元素
//创建方式对象创建,new
List<String> list = new ArrayList();
list.add("苹果");
list.add("香蕉");
System.out.println(list);
//创建一个数组
String[] strs = new String[2];
strs[0] = "苹果";
strs[1] = "香蕉";
System.out.println(strs[0]+" "+strs[1]);
}
}
|
输出
可以看到这里基本上是一样的。但是还是有区别的:
1.这里可以看出,我们通过数组的方式的话不可以直接全部读取的。
2.如果我们再次添加一个内容的,很难操作的,需要新建一个对象,然后再打印。这个问题的话在我们的集合里就很容易解决。
这就是集合的第一个特性。
集合的第二个特性
如果我再添加一个数据葡萄,让葡萄到第二个数据中,而香蕉再第三个数据中,那么怎么操作呢?
数组
1
2
3
4
5
6
|
String[] strs = new String[2];
strs[0] = "苹果";
strs[1] = "香蕉";
strs[2] = strs[1];//将str[1]内容赋值到2中
strs[1] = "葡萄"; //再将1内容重写
System.out.println(strs[0]+" "+strs[1]);
|
可以看到数组还是很麻烦的,需要两行代码才行。
List
1
2
3
4
5
|
List<String> list = new ArrayList();
list.add("苹果");
list.add("香蕉");
list.add(1,"葡萄"); //直接这一行代码即可,数据互换。
System.out.println(list);
|
获取指定的数据
直接使用list.get(0),可以直接获取0号元素的值。
1
2
3
4
5
6
7
|
List<String> list = new ArrayList();
list.add("苹果");
list.add("香蕉");
list.add(1,"葡萄");
System.out.println(list.get(0)); //这里get(0) 0是索引。
输出:苹果
|
List和数组的区别
1.List可以动态添加数据,而数组只能添加固定长度的数据。
2.List可以灵活插入指定位置的数据,数组较为复杂。
列表和链表的区别
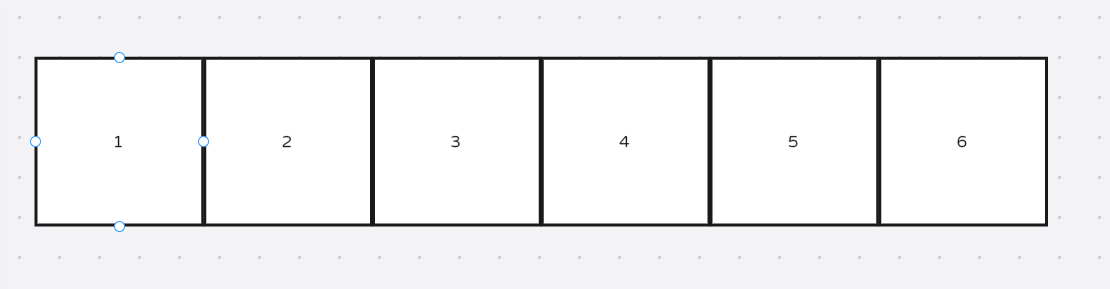
列表ArrayList
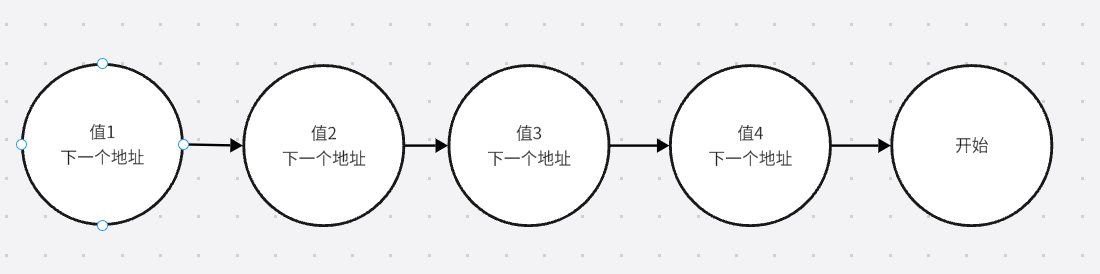
单链表
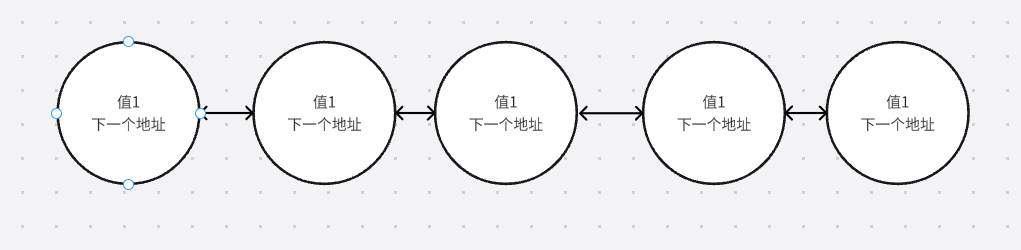
双向链表LinkedList
比较
当我们需要在中间插入一个数值的时候呢,谁更快?
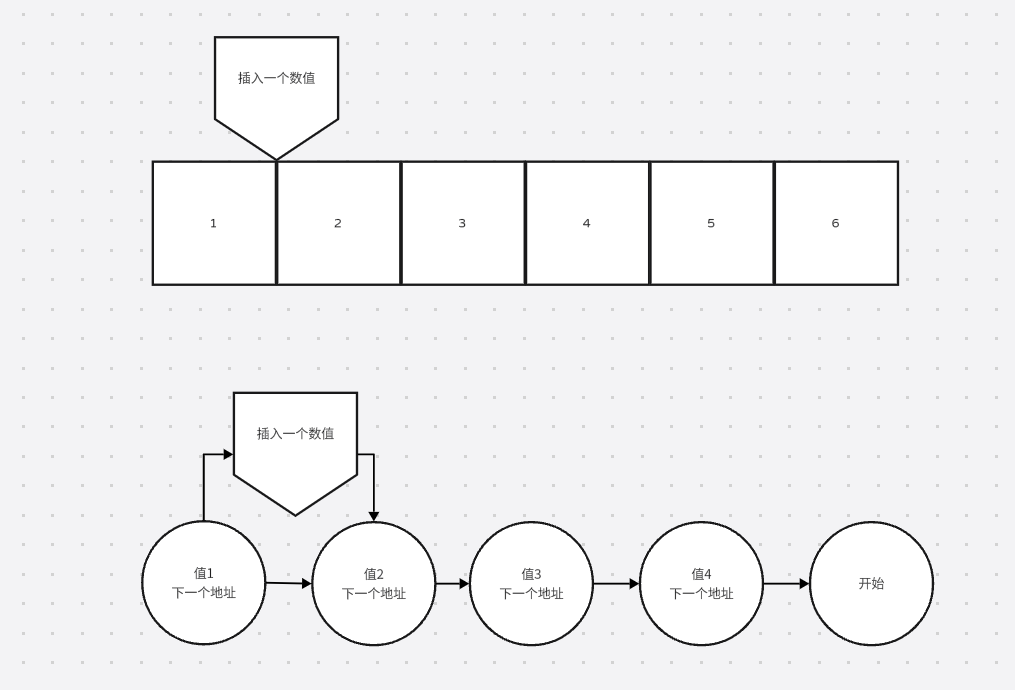
可以看到,如果插入一个数值的话,LinkedList比较块,直接指向就可以了。
ArrayList与LinkedList的区别
1.ArrayList查询更快,LinkedList查询慢,原因是LinkedList需要查询下一个地址。
2.LinkedList插入数据更快。
LinkedList的使用
创建和使用
1
2
3
4
5
6
7
|
List<String> linkedlist = new LinkedList();
linkedlist.add("李氏");
linkedlist.add("王氏");
linkedlist.addFirst("张氏"); //头部插入数据
linkedlist.addLast("丁氏"); //在尾部插入数据
System.out.println(linkedlist);
|
输出
遍历
依次读取元素里的值。
循环
for循环
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> linkedlist = new LinkedList();
linkedlist.add("李氏");
linkedlist.add("王氏");
linkedlist.addFirst("张氏"); //头部插入数据
linkedlist.addLast("丁氏"); //在尾部插入数据
//for循环实现遍历
for (int i = 0; i < linkedlist.size(); i++) {
System.out.println(linkedlist.get(i));
}
}
}
|
输出
迭代器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> linkedlist = new LinkedList();
linkedlist.add("李氏");
linkedlist.add("王氏");
linkedlist.addFirst("张氏"); //头部插入数据
linkedlist.addLast("丁氏"); //在尾部插入数据
//迭代器
//list元素,依次赋值给l 直到结束
for(String s: linkedlist){
System.out.println(s);
}
}
}
|
输出
修改
可以直接使用get进行修改,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> linkedlist = new LinkedList();
linkedlist.add("李氏");
linkedlist.add("王氏");
linkedlist.addFirst("张氏"); //头部插入数据
linkedlist.addLast("丁氏"); //在尾部插入数据
System.out.println("修改前"+linkedlist);
linkedlist.set(1,"西瓜");
System.out.println("修改后"+linkedlist);
}
}
|
输出
1
2
|
修改前[张氏, 李氏, 王氏, 丁氏]
修改后[张氏, 西瓜, 王氏, 丁氏]
|
删除
直接使用remove方法即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> linkedlist = new LinkedList();
linkedlist.add("李氏");
linkedlist.add("王氏");
linkedlist.addFirst("张氏"); //头部插入数据
linkedlist.addLast("丁氏"); //在尾部插入数据
linkedlist.remove(1);
System.out.println(linkedlist);
}
}
|
输出
2. set集合
特点
- 不重复且一性
- HashSet。
定义
泛型指定,只能指定对象。
1
2
3
4
5
6
7
8
9
10
11
12
|
import java.util.*;
public class Main {
public static void main(String[] args) {
Set<Integer> set = new HashSet<Integer>();
set.add(1);
set.add(2);
set.add(3);
System.out.println(set);
}
}
|
输出
并且他还会自己排序
特性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import java.util.*;
public class Main {
public static void main(String[] args) {
Set<Integer> set = new HashSet<Integer>();
set.add(1);
set.add(4);
set.add(6);
set.add(2);
set.add(3);
set.add(5);
System.out.println(set);
}
}
|
输出
可以看出,我们插入是数据是无序的,但是输出是有序的。
LinkedHashSet
这里就不过多解释,基本上和之前的一样。
定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import java.util.*;
public class Main {
public static void main(String[] args) {
Set<Integer> set = new LinkedHashSet<>();
set.add(1);
set.add(4);
set.add(6);
set.add(2);
set.add(3);
set.add(5);
System.out.println(set);
}
}
|
输出
特性一
使用
去重复
假如我这边有一个数组,里面都是重复项,我这边需要对所有元素进行去重处理,这时候我们就可以使用Set集合进行处理。
代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import java.util.*;
public class Main {
public static void main(String[] args) {
int[] ints = new int[10];
ints[0] = 1;
ints[1] = 2;
ints[2] = 1;
ints[3] = 2;
ints[4] = 2;
ints[5] = 2;
ints[6] = 1;
ints[7] = 8;
ints[8] = 9;
Set<Integer> set = new HashSet<>();
for (int i = 0; i < ints.length; i++) {
set.add(ints[i]);
}
System.out.println(set);
}
}
|
输出
TreeSet
使用案例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// 导入java.util包下的所有类(如Set、TreeSet、Collections等)
import java.util.*;
// 定义主类Main(Java程序入口类)
public class Main {
// 主方法,程序执行的入口点
public static void main(String[] args) {
// 1. 创建TreeSet集合,并指定排序规则为"自然排序的逆序(降序)"
// - TreeSet是有序集合,默认按元素自然顺序(升序)排列
// - Collections.reverseOrder()返回一个比较器,实现逆序排序
Set<Integer> set = new TreeSet<>(Collections.reverseOrder());
// 2. 向集合中添加整数元素
set.add(1);
set.add(2);
set.add(3);
set.add(4);
set.add(5);
set.add(6);
set.add(7);
set.add(8);
// 3. 打印集合内容(由于指定了降序,输出结果为[8, 7, 6, 5, 4, 3, 2, 1])
System.out.println(set);
}
}
|
交集/并集的使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
// 导入java.util包下的所有类(如Set、HashSet、Arrays等)
import java.util.*;
// 定义主类Main
public class Main {
// 主方法,程序入口
public static void main(String[] args) {
// 创建第一个HashSet集合set1,并通过Arrays.asList快速初始化元素为1,2,3
// HashSet是无序集合,不保证元素的存储顺序,但元素唯一(无重复)
Set<Integer> set1 = new HashSet<>(Arrays.asList(1, 2, 3));
// 创建第二个HashSet集合set2,初始化元素为2,3,4
Set<Integer> set2 = new HashSet<>(Arrays.asList(2, 3, 4));
// 计算两个集合的交集(即同时存在于set1和set2中的元素)
// 1. 先创建一个新的HashSet集合set3,并将set1的所有元素复制到set3中
Set<Integer> set3 = new HashSet<>(set1);
// 2. 调用retainAll方法,保留set3中与set2共有的元素(删除不共有的元素)
set3.retainAll(set2);
// 打印交集结果,应为[2, 3](HashSet无序,输出顺序可能不同)
System.out.println(set3);
// 计算两个集合的并集(即包含set1和set2中所有的元素,去重)
// 1. 创建新的HashSet集合set4,并复制set1的所有元素
Set<Integer> set4 = new HashSet<>(set1);
// 2. 调用addAll方法,将set2的所有元素添加到set4中(自动去重)
set4.addAll(set2);
// 打印并集结果,应为[1, 2, 3, 4](HashSet无序,输出顺序可能不同)
System.out.println(set4);
}
}
|
0x01 Map
在 Java 中,Map 是一种键值对(Key-Value) 形式的集合接口,用于存储和管理具有映射关系的数据。它不属于 Collection 接口体系,是独立的顶层接口,核心思想是 “通过键(Key)快速查找值(Value)”。
Map 的核心特点
- 键值对映射:每个元素由一个
Key 和一个 Value 组成,通过 Key 可以唯一确定 Value。
- 键的唯一性:
Key 不允许重复(若添加相同 Key,新的 Value 会覆盖旧值)。
- 值可以重复:
Value 可以相同,无唯一性约束。
- 无序性(部分实现有序):默认情况下,
Map 的实现类(如 HashMap)不保证元素的存储顺序;但 LinkedHashMap 可保证插入顺序,TreeMap 可保证键的排序顺序。
使用
定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import java.util.*;
public class Main {
public static void main(String[] args) {
//创建
Map<Integer, String> map = new HashMap<>();
//添加
map.put(1, "苹果");
map.put(2, "香蕉");
map.put(3, "梨");
//打印
System.out.println(map);
}
}
|
输出
查
1
2
3
|
System.out.println(map.get(1));
//输出
苹果
|
注意:如果key值相同,会覆盖上一个值
修改
1
2
3
4
|
map.put(3,"你搞");
System.out.println(map);
输出:
{1=苹果, 2=香蕉, 3=你搞}
|
删除
1
2
3
4
|
map.remove(2);
System.out.println(map);
输出:
{1=苹果, 3=你搞}
|
总结
Map 是处理键值对数据的核心工具,适用于需要通过唯一标识(键)快速查找数据(值)的场景,如配置信息、缓存、字典等。根据需求选择合适的实现类(如追求效率用 HashMap,需要顺序用 LinkedHashMap,需要排序用 TreeMap)。
